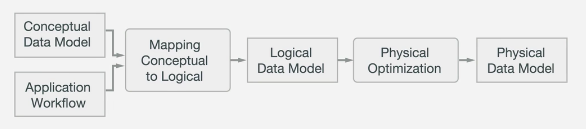
Data Modeling
DS220 Data Modeling
- Analyze requirements
- Identify entities and relationships
- Identify queries
- Specify the schema
- Optimize, optimize, optimize
- CQL
Case Study
KillrVideo, Inc.
Problems
- Scalability
- Reliability
- Ease of use
Solutions Attempted
Relational Database Problem
- Single points of failure
- Scaling complexity
- Reliability issues
- Difficult to serve users worldwide
WHy Cassandra
- Peers instead of master/slave
- Linear scale performance
- Always on reliability
- Data can be stored geographically close to clients
Keyspaces
Top-level namespace/container
Replication parameters required
CREATE KEYSPACE killrvideo
WITH replication = {'class': 'SimpleStrategy',
'replication_factor': 1
};
Use
- USE switches between keyspaces
USE killrvideo ;
Tables
- keyspaces contain tables
- tables contain data

Primary Keyys
Basic Data types
- text
- int
- UUID (Universally Unique Identifier)
- Generate via uuid()
- the third part begin with 4
- TIMEUUID embeds a TIMESTAMP value
- Sortable
- Generate viad now()
- the third part begin with 1
- TIMESTAMP
- Milliseconds since January 1 1970 at 00:00:00 MT
- Displayed in cqlsh as yyyy-mm-dd HH:mm:ssZ
COPY
- Imports/exports CSV
COPY table1 (column1, column2, column3) FROM 'table1data.csv'; - Header parameter skips the first line in the file
COPY table1 (column1, column2, column3) FROM 'table1data.csv' WITH HEADER=true;
SELECT
SELECT *
FROM table1;
SELECT column1, column2, column3
FROM table1;
SELECT COUNT(*)
FROM table1;
SELECT *
FROM table1
LIMIT 10;
Exercise 2
Create Keyspaces
CREATE KEYSPACE killrvideo WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1};
Create Table
CREATE TABLE videos (
video_id timeuuid ,
added_date timestamp ,
description text ,
title text ,
user_id uuid ,
primary KEY (video_id)
);
Describe Table
DESCRIBE TABLE videos ;
Import CSV file
COPY videos FROM 'videos.csv' WITH HEADER= true ;
Select
SELECT * FROM videos LIMIT 10;
SELECT count(*) FROM videos ;
Exercise 3
USE killrvideo ;
CREATE TABLE videos_by_title_year (
title text ,
added_year int ,
added_date timestamp ,
description text ,
user_id uuid ,
video_id uuid ,
primary KEY ((title, added_year))
) ;
COPY videos_by_title_year FROM 'videos_by_title_year.csv' WITH HEADER= true ;
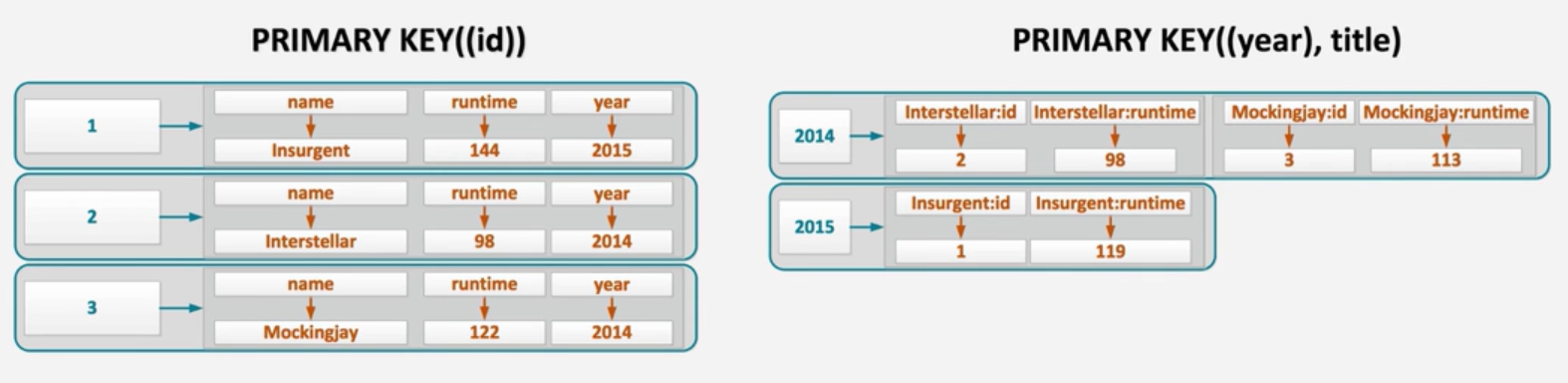
SELECT * FROM videos_by_title_year WHERE title= 'Sleepy Grumpy Cat' and added_year = 2015;
if query the table with only title of added_year, the system will return an error
SELECT * FROM videos_by_title_year WHERE title= 'Sleepy Grumpy Cat' ;
The reason is that, cassandra use partition key to calculate the hash code, and use hash code to find the place of value.
keyspace --> partition --> clustering columns
Partition keys determine a grouping criteria whereas clustering columns determine ordering criteria
Exercise 4
USE killrvideo ;
CREATE TABLE bad_videos_by_tag_year_table (
tag text,
added_year int,
added_date timestamp,
title text,
description text,
user_id uuid,
video_id timeuuid,
PRIMARY KEY ((video_id))
);
DESCRIBE TABLE bad_videos_by_tag_year_table ;
COPY bad_videos_by_tag_year_table (tag, added_year, video_id, added_date, description, title, user_id) FROM 'videos_by_tag_year.csv' WITH HEADER=true;
SELECT count(*) FROM bad_videos_by_tag_year_table ;
DROP TABLE bad_videos_by_tag_year_table ;
with this example, because some video_id are same, thus the following will be treated as upsert for the table. Some records are overlaped.
Recreate a table
CREATE TABLE videos_by_tag_year (
tag text,
added_year int,
video_id timeuuid,
added_date timestamp,
description text,
title text,
user_id uuid,
PRIMARY KEY ((tag), added_year, video_id)
) WITH CLUSTERING ORDER BY (added_year DESC);
DESCRIBE TABLE videos_by_tag_year ;
COPY videos_by_tag_year FROM 'videos_by_tag_year.csv' WITH HEADER=true;
SELECT COUNT (*) FROM videos_by_tag_year ;
SELECT * FROM videos_by_tag_year WHERE tag = 'trailer' and added_year = 2015 ;
SELECT * FROM videos_by_tag_year WHERE tag = 'cql' and added_year = 2013 ;
SELECT * FROM videos_by_tag_year WHERE tag = 'cql' and added_year < 2015 ;